
Swift 2: SIMD
Single Instruction, Multiple Awesome
Swift 2 brings updated support for SIMD (Single Instruction Multiple Data). What exactly does that mean?
SIMD Primer
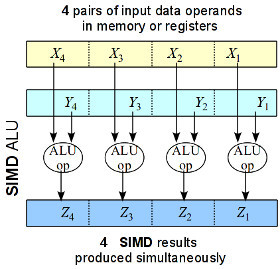
Each CPU vendor has their own unique snowflake versionº but the premise is the same: process data in parallel chunks. Each SIMD instruction operates on a group of values organized into what are called "lanes". Let's take a typical 128-bit SIMD register. You can load it with four Float values or two Double values, corresponding to two 2D float vectors or a single 4D Float/2D Double vector.
Not all versions of all processors support the same numbers of arguments at the same levels of precision or the same operations; MMX was integer only and re-used the x86 FP registers (but made them directly addressable instead of using a stack format), making it difficult to mix floating-point and MMX code. Early SSE was single-precision floating point only but introduced separate registers. SSE2 allows operating on integers (making MMX redundant) and double precision floats but the registers are the same size so you get fewer operands. AMD's 64-bit extensions to x86 doubled the number of SSE registers. Intel brought new operations like dot product in SSE 4. ARM's NEON is different yet again.
These days most processors let you slice and dice the 128-bit (or 256-bit) registers into a varied number of integer or floating point values at various precision levels.
Enter simd.h: This built-in library gives us a standard interface for working with 2D, 3D, and 4D vector and matrix operations across various processors on OS X and iOS. It automatically falls back to software routines if the CPU doesn't natively support the given operation (for example splitting up a 4-lane vector into two 2-lane operations). It also has the bonus of easily transferring data between the GPU and CPU using Metal.
If you're curious, check out the WWDC 2014 session What's new in the Accelerate Framework; skip forward to the simd.h section.
You may wonder how Accelerate's vDSP/vImage and Metal fit into this story:
| Tech | What | CPU/GPU |
|---|---|---|
| simd.h | Vector, Matrix, and Graphics; standardized basic types like vector and matrix | CPU SIMD, with non-SIMD fallback |
| vDSP | Digital Signal Processing (FFT, etc) | CPU SIMD, with non-SIMD fallback |
| vImage | Image Processing | CPU SIMD, with non-SIMD fallback |
| Metal | Graphics and parallel compute | GPU |
The Swift Story
In Swift 1.2 you could @import simd but it wouldn't do you much good. The compiler has to map the types to intrinsics, support certain alignment requirements and padding, etc. Swift 1.2 didn't know how to do any of that so vector extensions were basically unusable.
In Swift 2 that has changed. All the types are present and have full operator implementations. They all have handy initializers (vector initialized to a scalar value, a matrix with diagonals set, and so on). They can convert between the C/Objective-C types quite easily. They have full operator support, including between types so you can multiply a vector and a matrix with wild abandon:
import simd
let vec = float3(1.0, 1.0, 1.0)
let matrix = float3x3()
//wheeeee!
let result = vec * matrix
You'll also find dot product, cross product, reciprocal, length, reflect, refract, min, max, reduce_add, and more. It's nice to have these operations built-in (and presumably tested and known to be correct), even putting the performance benefits aside.
The type names all follow a standard convention of <type><dimension>. Some examples:
int2- a vector of two 32-bit integersfloat3- a single-precision vector of three componentsdouble3x4- a double-precision matrix with three columns and four rows
Again, it's nice to have standard vector and matrix types even without considering performance.
Example
For testing, I'm using code inspired by Raymond Chen. The operations don't map exactly but it should be good enough. I would normally use integers but simd.h doesn't define sign for the integer types, nor does it support the logic.h macros as of yet so I had to use a roundabout way of doing the counts. To make it more Apples-to-Apples I did the standard loop comparison in the same convoluted way.
The goal of this simplistic example code is to repeatedly count how many random numbers are below some boundary. For the regular loop we'll use a flat array and for the vector loop we'll use an array of Float4:
//Setup stuff
let array = (0..<10000).map { (_) in Float(rand() % 10) }
let vecArray = stride(from: 0, to: array.count, by: 4)
.map { (i:Int) -> float4 in
float4(array[i], array[i + 1], array[i + 2], array[i + 3])
}
First let's look at the convoluted "normal" implementation:
func doNormalCount() {
for boundary in 0...10 {
let negBoundary = -Float(boundary - 1)
var total = 0
let timer = HighResolutionTimer()
for _ in 0..<1000 {
var count = Float()
for var i in array {
i += negBoundary
i = sign(i)
i = max(i, 0)
count += i
}
total += (array.count - Int(count))
}
let elapsed = timer.elapsed()
print("NORM: count = \(total), time = \(elapsed)ms")
}
}
We run a check for each boundary from zero to 10, using a timer struct to count how long it takes. Then we run 100 iterations of the count to smooth out minor variations. The logic in the inner loop is a silly way to count whether something is below the boundary but it matches what we have to do on the SIMD side.
Here is the SIMD version:
func doSimdCount() {
for boundary in 0...10 {
let negBoundary = float4(-Float(boundary - 1))
var total = 0
let timer = HighResolutionTimer()
for _ in 0..<1000 {
var counts = float4()
for i in 0..<vecArray.count {
var v = vecArray[i]
v += negBoundary
v = sign(v)
v = max(v, 0.0)
counts += v
}
total += (array.count - Int(reduce_add(counts)))
}
let elapsed = timer.elapsed()
print("SIMD: count = \(total), time = \(elapsed)ms")
}
}
You might be tempted to think getting rid of the v temporary would improve performance but you'd be wrong; in optimized builds Swift/LLVM is smart enough to handle this automatically. I also tested a version with a manually unrolled loop and it was consistently slower; the LLVM backend's automatic loop unrolling did a far better job of using the available registers (confirmed by looking at the disassembly). Swift also aggressively inlines the simd.h functions, eliminating function call overhead.
Results
Tests compiled with -O -whole-module-optimization and SWIFT_DISABLE_SAFETY_CHECKS. Times have some amount of jitter but are representative of repeated executions.
| Count | Normal Time | SIMD Time |
|---|---|---|
| 0 | 17.311ms | 14.185ms |
| 100100 | 24.150ms | 15.157ms |
| 200100 | 31.519ms | 14.480ms |
| 296100 | 41.816ms | 14.249ms |
| 398300 | 55.993ms | 13.922ms |
| 499100 | 59.485ms | 17.397ms |
| 599000 | 65.972ms | 21.257ms |
| 698500 | 64.062ms | 19.751ms |
| 800400 | 52.136ms | 20.532ms |
| 896000 | 37.534ms | 14.487ms |
| 1000000 | 17.347ms | 13.440ms |
The first thing that might jump out at you (if you didn't read the Raymond Chen link) is the crazy performance characteristics of the Normal method. That boils down to branch prediction; sign is doing a branch and when the boundary is in the middle the branch essentially takes a random direction every iteration of the loop so we get a huge misprediction penalty. If you check the disassembly you'll see that LLVM has generated SIMD instructions to do the floating point, but operating on one value at a time. I believe that all modern compilers do this to avoid the crappy x87 stack-based floating point but I couldn't find a citation to prove it.
Looking at the SIMD results we can see there may still be a branch somewhere but it isn't nearly as expensive. We also see that SIMD is faster all cases and in the worst-case scenario it's three times as fast.
Warning: This is a horribly artificial benchmark; do not take it as proof of anything. I made no attempt to measure the impact on battery life, which can have huge implications. Please profile your own code using optimized builds!
Conclusion
SIMD is a technology that spans the gap between GPU shaders and old-fashioned CPU instructions, allowing the CPU to issue a single instruction that crunches chunks of data in parallel.
Swift 2 brings us native support for that technology and papers over all the various architectural differences to give a clean abstract interface. Apple has also gone the extra mile to ensure that they are using a consistent set of types across various technologies and processors, making it much easier to share workloads.
If you find yourself working with vectors or matrices you should immediately think import simd. Signal processing? Use VDSP. Image processing? Try vImage or CoreImage. Your benchmarks and battery life will thank you.
º: MMX, AltiVec, 3DNow, SSE, and NEON just to name a few
*: As always, corrections and comments are appreciated.
This blog represents my own personal opinion and is not endorsed by my employer.